
接口依赖之业务流
前面讲的接口依赖都是单接口测试时的场景。
接口自动化的另一个接口依赖场景是业务流。
总结一下,接口自动化时怎么处理接口依赖 这个问题的回答如下:
对于单接口测试如果依赖接口只需要在测试开始执行一次,那么可以将依赖接口的请求放在类级前置方法中,然后通过全局变量或者当前用例类属性来传递依赖数据。
对于单接口测试如果依赖接口需要在每个用例前执行,那么可以将依赖接口的请求放在方法级前置方法中,然后通过用例对象属性来传递依赖数据
对于多接口的业务流测试,可以将下一个接口需要依赖的数据通过当前用例类属性来传递依赖数据。
1. 接口测试业务流程设计
- 站在用户的角度,从产品业务出发
- 重视全局而非细节
- 先测主流程,后测分流程
- 只测正例
2. 前程贷业务流
投资流程
- 注册普通融资用户
- 登录普通融资用户
- 创建融资项目
- 注册管理员用户
- 登录管理员用户
- 审核融资项目
- 注册普通投资用户
- 登录普通投资用户
- 充值
- 投资项目
3. 代码实现
3.1 方案1
- 在测试用例类中根据业务流,按顺序一个请求定义一个对应的单元测试方法。
- 并将下一个接口需要用到的数据绑定到类属性中进行传递
优点: 逻辑清晰简单
缺点: 1. 当业务流很长的时候代码量会比较大 2. 业务发生改变的时候需要修改代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/12/11 17:33
# @Author : shisuiyi
# @File : test_invest_flow.py
# @Software: win10 Tensorflow1.13.1 python3.9
from common.base_case import BaseCase
from common.data_handler import get_data_from_excel
from unittestreport import ddt, list_data
class TestInvestFlow(BaseCase):
name = '投资业务流'
def test_01register_normal_user(self):
"""
1.注册普通融资用户
:return:
"""
item = {'title': '注册普通融资用户',
'method': 'post',
'url': 'register',
'request_data': '{"headers": {"X-Lemonban-Media-Type": "lemonban.v1"},"json": {"mobile_phone":$phone_number$,"pwd":"12345678"}}',
'status_code': 200,
'res_type': 'json',
'expect_data': '{"code":0,"msg":"OK"}',
'sql': 'select id from member where mobile_phone=$phone_number$'}
self.flow(item)
# 绑定下一个测试需要的数据
# 在响应中可以拿数据,并绑定到类属性中
self.__class__.normal_mobile_phone = self._response.json()['data']['mobile_phone']
# 在self._case中也可以拿到数据
def test_02login_normal_user(self):
"""
2.登录普通融资用户
:return:
"""
item = {
'title': '登录融资用户',
'url': 'login',
'method': 'post',
'request_data': '{"headers": {"X-Lemonban-Media-Type": "lemonban.v2"},"json": {"mobile_phone":#normal_mobile_phone#,"pwd":"12345678"}}',
'status_code': 200,
'res_type': 'json',
'expect_data': '{"code":0,"msg":"OK"}'
}
self.flow(item)
# 在响应中提取下一个接口需要的数据然后绑定到类属性上
self.__class__.normal_token = self._response.json()['data']['token_info']['token']
self.__class__.normal_member_id = self._response.json()['data']['id']
def test_03add_loan(self):
"""
3.创建融资项目
:return:
"""
item = {
'title': '添加融资项目',
'url': 'add',
'method': 'post',
'request_data': '''{"headers": {"X-Lemonban-Media-Type": "lemonban.v2", "Authorization":"Bearer #normal_token#"},
"json": {"member_id":#normal_member_id#,
"title":"借钱实现财务自由",
"amount":5000,
"loan_rate":18.0,
"loan_term":6,
"loan_date_type":1,
"bidding_days": 10
}}''',
'status_code': 200,
'res_type': 'json',
'expect_data': '{"code":0,"msg":"OK"}'
}
self.flow(item)
self.__class__.loan_id = self._response.json()['data']['id']
def test_04register_admin_user(self):
"""
4.注册管理员用户
:return:
"""
item = {
'title': '注册管理员用户',
'url': 'register',
'method': 'post',
'request_data': '{"headers": {"X-Lemonban-Media-Type": "lemonban.v1"},"json": {"mobile_phone":$phone_number$,"pwd":"12345678","type":0}}',
'status_code': 200,
'res_type': 'json',
'expect_data': '{"code":0,"msg":"OK"}',
'sql': 'select id from member where mobile_phone=$phone_number$'
}
self.flow(item)
self.__class__.admin_mobile_phone = self._response.json()['data']['mobile_phone']
def test_05login_admin_user(self):
"""
5. 登录管理员
:return:
"""
item = {
'title': '登录管理员用户',
'url': 'login',
'method': 'post',
'request_data': '{"headers": {"X-Lemonban-Media-Type": "lemonban.v2"},'
'"json": {"mobile_phone":#admin_mobile_phone#,"pwd":"12345678"}}',
'status_code': 200,
'res_type': 'json',
'expect_data': '{"code":0,"msg":"OK"}'
}
self.flow(item)
self.__class__.admin_token = self._response.json()['data']['token_info']['token']
def test_06audit_loan(self):
"""
6. 审核融资项目
:return:
"""
item = {
'title': '登录管理员用户',
'url': 'login',
'method': 'post',
'request_data': '{"headers": {"X-Lemonban-Media-Type": "lemonban.v2"},'
'"json": {"mobile_phone":#admin_mobile_phone#,"pwd":"12345678"}}',
'status_code': 200,
'res_type': 'json',
'expect_data': '{"code":0,"msg":"OK"}'
}
self.flow(item)
self.__class__.admin_token = self._response.json()['data']['token_info']['token']
def test_07register_invest_user(self):
"""
7.注册普通投资用户
:return:
"""
item = {
'title': '注册投资用户',
'url': 'register',
'method': 'post',
'request_data': '{"headers": {"X-Lemonban-Media-Type": "lemonban.v1"},"json": {"mobile_phone":$phone_number$,"pwd":"12345678"}}',
'status_code': 200,
'res_type': 'json',
'expect_data': '{"code":0,"msg":"OK"}',
'sql': 'select id from member where mobile_phone=$phone_number$'
}
self.flow(item)
self.__class__.invest_mobile_phone = self._response.json()['data']['mobile_phone']
def test_08login_invest_user(self):
"""
8. 登录普通投资用户
:return:
"""
item = {
'title': '登录融资用户',
'url': 'login',
'method': 'post',
'request_data': '{"headers": {"X-Lemonban-Media-Type": "lemonban.v2"},"json": {"mobile_phone":#invest_mobile_phone#,"pwd":"12345678"}}',
'status_code': 200,
'res_type': 'json',
'expect_data': '{"code":0,"msg":"OK"}'
}
self.flow(item)
self.__class__.invest_token = self._response.json()['data']['token_info']['token']
self.__class__.invest_member_id = self._response.json()['data']['id']
def test_09invest_user_recharge(self):
"""
9. 普通投资用户充值
:return:
"""
item = {
'title': '投资用户充值',
'url': 'recharge',
'method': 'post',
'request_data': '{"headers": {"X-Lemonban-Media-Type": "lemonban.v2","Authorization":"Bearer #invest_token#"},'
'"json": {"member_id":#invest_member_id#,"amount":888}}',
'status_code': 200,
'res_type': 'json',
'expect_data': '{"code":0,"msg":"OK"}'
}
self.flow(item)
def test_10invest(self):
"""
10. 投资
:return:
"""
item = {
'title': '投资',
'url': 'recharge',
'method': 'post',
'request_data': '{"headers": {"X-Lemonban-Media-Type": "lemonban.v2","Authorization":"Bearer #invest_token#"},'
'"json": {"member_id":#invest_member_id#,"amount":888,"loan_id":#loan_id#}}',
'status_code': 200,
'res_type': 'json',
'expect_data': '{"code":0,"msg":"OK"}'
}
self.flow(item)
3.2 方案2
思路: 将业务流也做成数据驱动 优点:
- 代码复用,基本流程不变,基本上可以一劳永逸
- 当业务流发生改变的时候,只需要修改用例数据而不用修改代码
缺点:
- 学习成本高,需要对代码逻辑了解才能编写用例数据
3.2.1 用例数据设计
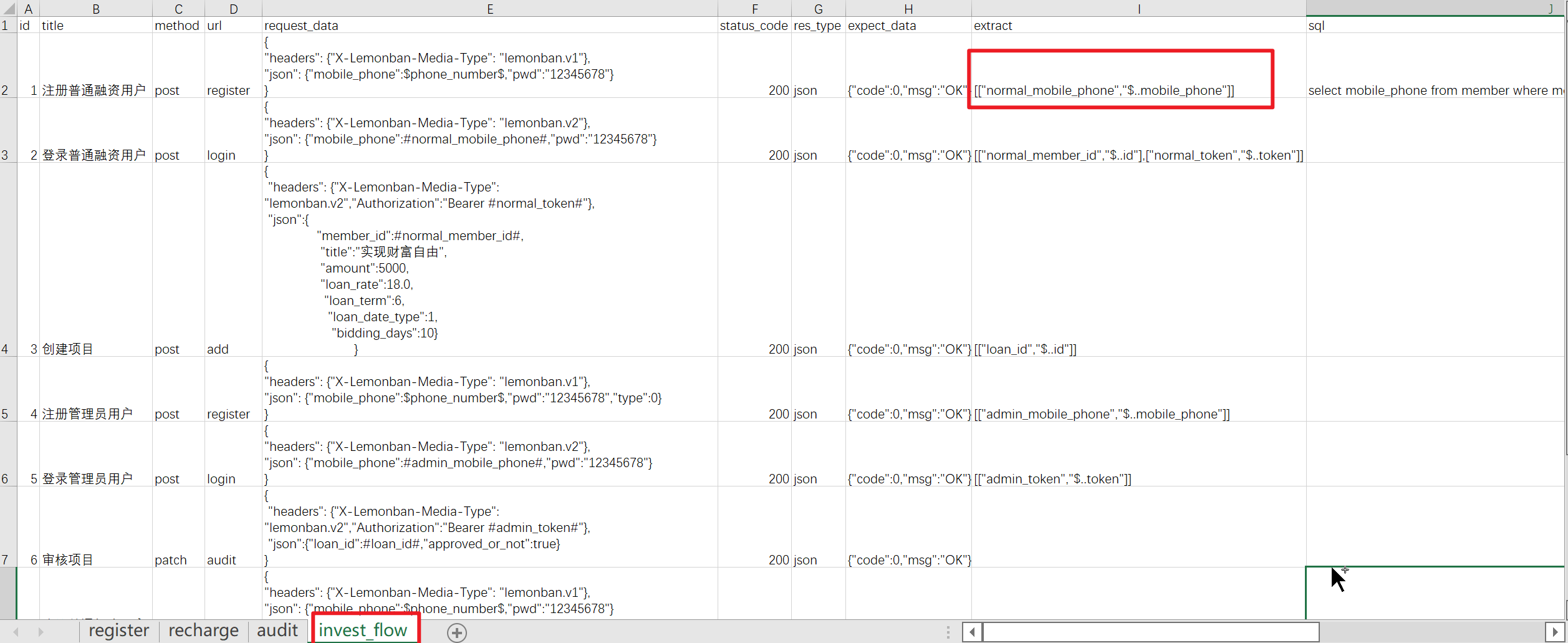
在用例数据中添加一栏extract表示提取响应数据并保存到对应的类属性中,规则如下: [["member_id","$..id"],["token","$..token"]]
上面的提取规则是一个嵌套的数组,每一个子数组的第一个元素表示要绑定的类属性名,第二个元素表示从json响应数据中提取数据的jsonpath提取表达式。
3.2.2 jsonpath模块
从json格式中提取数据,通过字符串格式的提取表达式。 安装:
pip install jsonpath


data = {
"store": {
"book": [
{"category": "参考",
"author": "Nigel Rees",
"title": "世纪风俗",
"price": 8.95
},
{"category": "小说",
"author": "Evelyn Waugh",
"title": "荣誉剑",
"price": 12.99
},
{"category": "小说",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{"category": "小说",
"author": "JRR Tolkien",
"title": "指环王",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
from jsonpath import jsonpath
# 提取成功后返回一个列表,如果提取不到返回False
jsonpath(data, '$.store.book.0.title') # 第一本书的名称
输出
['世纪风俗']
jsonpath(data, '$.store.book.*.author') # 所有书的作者
jsonpath(data, '$.store.book.[*].author')
输出
['Nigel Rees', 'Evelyn Waugh', 'Herman Melville', 'JRR Tolkien']
jsonpath(data, '$.store..price') # store所有物品的价格
输出
[8.95, 12.99, 8.99, 22.99, 19.95]
jsonpath(data, '$..book[1]') # 第二本书
输出
[{'category': '小说', 'author': 'Evelyn Waugh', 'title': '荣誉剑', 'price': 12.99}]
jsonpath(data, '$..book[(@.length-1)]') # 最后一本书,不支持负索引
输出
[{'category': '小说',
'author': 'JRR Tolkien',
'title': '指环王',
'isbn': '0-395-19395-8',
'price': 22.99}]
jsonpath(data, '$..book[-1:]') # 支持切片,最后一本书
输出
[{'category': '小说',
'author': 'JRR Tolkien',
'title': '指环王',
'isbn': '0-395-19395-8',
'price': 22.99}]
jsonpath(data, '$..book[0,2]') # 枚举索引
输出
[{'category': '参考', 'author': 'Nigel Rees', 'title': '世纪风俗', 'price': 8.95},
{'category': '小说',
'author': 'Herman Melville',
'title': 'Moby Dick',
'isbn': '0-553-21311-3',
'price': 8.99}]
jsonpath(data, '$..book[?(@.isbn)]') # 过滤所有isbn的书
输出
[{'category': '小说',
'author': 'Herman Melville',
'title': 'Moby Dick',
'isbn': '0-553-21311-3',
'price': 8.99},
{'category': '小说',
'author': 'JRR Tolkien',
'title': '指环王',
'isbn': '0-395-19395-8',
'price': 22.99}]
jsonpath(data, '$..book[?(@.price<10)]')
输出
[{'category': '参考', 'author': 'Nigel Rees', 'title': '世纪风俗', 'price': 8.95},
{'category': '小说',
'author': 'Herman Melville',
'title': 'Moby Dick',
'isbn': '0-553-21311-3',
'price': 8.99}]
3.2.3 提取函数封装
功能分析:
- 根据
jsonpath表达式动态提取现有结果中的数据 - 动态绑定数据到指定的对象
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/12/11 11:12
# @Author : shisuiyi
# @File : base_case.py
# @Software: win10 Tensorflow1.13.1 python3.9
import json
import unittest
from jsonpath import jsonpath
import setting
from common import logger, db
from common.data_handler import (
replace_args_by_re,
generate_no_usr_phone)
from common.make_requests import send_http_request
class BaseCase(unittest.TestCase):
"""
用例基类
"""
db = db
logger = logger
setting = setting
name = 'base_case'
@classmethod
def setUpClass(cls) -> None:
cls.logger.info('==========={}接口开始测试==========='.format(cls.name))
@classmethod
def tearDownClass(cls) -> None:
cls.logger.info('==========={}接口结束测试==========='.format(cls.name))
def flow(self, item):
"""
测试流程
"""
self.logger.info('>>>>>>>用例{}开始执行>>>>>>>>'.format(item['title']))
# 把测试数据绑定到方法属性case上,其他也要把一些变量绑定到对象的属性上
self._case = item
# 1. 处理测试数据
self.process_test()
# 2. 发送请求
self.send_request()
# 3. 断言
self.assert_all()
def process_test(self):
"""
测试数据的处理
"""
# 1.1 生成测试数据
self.generate_test_data()
# 1.2 替换依赖参数
self.replace_args()
# 1.3 处理url
self.process_url()
def generate_test_data(self):
"""
生成测试数据
"""
"""
生成测试数据,不是固定流程,有不同可以复写
:return:
"""
self._case = json.dumps(self._case)
if '$phone_number$' in self._case:
phone = generate_no_usr_phone()
self._case = self._case.replace('$phone_number$', phone)
self._case = json.loads(self._case)
def replace_args(self):
"""
替换参数
"""
self._case = json.dumps(self._case) # 把用例数据dumps成字符串,一次替换
self._case = replace_args_by_re(self._case, self)
self._case = json.loads(self._case)
# 再将request_data, expect_data loads为字典
try:
self._case['request_data'] = json.loads(self._case['request_data'])
self._case['expect_data'] = json.loads(self._case['expect_data'])
except Exception as e:
self.logger.error('{}用例的测试数据格式不正确'.format(self._case['title']))
raise e
def process_url(self):
"""
处理url
"""
if self._case['url'].startswith('http'):
# 是否是全地址
pass
elif self._case['url'].startswith('/'):
# 是否是短地址
self._case['url'] = self.setting.PROJECT_HOST + self._case['url']
else:
# 接口名称
try:
self._case['url'] = self.setting.INTERFACES[self._case['url']]
except Exception as e:
self.logger.error('接口名称:{}不存在'.format(self._case['url']))
raise e
def send_request(self):
"""
发送请求
@return:
"""
self._response = send_http_request(url=self._case['url'], method=self._case['method'],
**self._case['request_data'])
def assert_all(self):
try:
# 3.1 断言响应状态码
self.assert_status_code()
# 3.2 断言响应数据
self.assert_response()
# 响应结果断言成功后就提取依赖数据
self.extract_data()
# 3.3 数据库断言后面的任务
self.assert_sql()
except Exception as e:
self.logger.error('++++++用例{}测试失败'.format(self._case['title']))
raise e
else:
self.logger.info('<<<<<<<<<用例{}测试成功<<<<<<<'.format(self._case['title']))
def assert_status_code(self):
"""
断言响应状态码
"""
try:
self.assertEqual(self._case['status_code'], self._response.status_code)
except AssertionError as e:
self.logger.warning('用例【{}】响应状态码断言异常'.format(self._case['title']))
raise e
else:
self.logger.info('用例【{}】响应状态码断言成功'.format(self._case['title']))
def assert_response(self):
"""
断言响应数据
"""
if self._case['res_type'].lower() == 'json':
res = self._response.json()
elif self._case['res_type'].lower() == 'html':
# 扩展思路
res = self._response.text
try:
self.assertEqual(self._case['expect_data'], {'code': res['code'], 'msg': res['msg']})
except AssertionError as e:
self.logger.warning('用例【{}】响应数据断言异常'.format(self._case['title']))
self.logger.warning('用例【{}】期望结果为:{}'.format(self._case['title'], self._case['expect_data']))
self.logger.warning('用例【{}】的响应结果:{}'.format(self._case['title'], res))
raise e
else:
self.logger.info('用例【{}】响应数据断言成功'.format(self._case['title']))
def assert_sql(self):
"""
断言数据库
"""
if self._case.get('sql'): # 返回指定键的值,如果键不在字典中返回默认值 None 或者设置的默认值。
# 只有sql字段有sql的才需要校验数据库
try:
self.assertTrue(self.db.exist(self._case['sql']))
except AssertionError as e:
self.logger.warning('用例【{}】数据库断言异常,执行的sql为:{}'.format(self._case['title'], self._case['sql']))
raise e
def extract_data(self):
"""
根据提取表达式提取对应的数据
:return:
"""
if self._case.get('extract'):
if self._case['res_type'].lower() == 'json':
self.extract_data_from_json()
elif self._case['res_type'].lower() == 'html':
self.extract_data_from_html()
elif self._case['res_type'].lower() == 'xml':
self.extract_data_from_xml()
else:
raise ValueError('res_type类型不正确,只支持json,html,xml')
def extract_data_from_json(self):
"""
从json数据中提取数据并绑定到类属性中
:return:
"""
try:
rules = json.loads(self._case.get('extract'))
except Exception as e:
raise ValueError('用例【{}】的extract字段数据:{}格式不正确'.format(self._case['title'], self._case['extract']))
for rule in rules:
# 类属性名
name = rule[0]
# 提取表达式
exp = rule[1]
# 根据jsonpath去响应中提取值
value = jsonpath(self._response.json(), exp)
# 如果能提取到值
if value:
# 把值绑定到对应的类属性上
setattr(self.__class__, name, value[0]) # 注意value是个列表
else:
# 提取不到值,说明jsonpath写错了,或者是响应又问题
raise ValueError('用例【{}】的提取表达式{}提取不到数据'.format(self._case['title'], self._case['extract']))
def extract_data_from_html(self):
"""
从html数据中提取数据并绑定到类属性中
:return:
"""
raise ValueError('请实现此方法')
def extract_data_from_xml(self):
"""
从xml数据中提取数据并绑定到类属性中
:return:
"""
raise ValueError('请实现此方法')
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/12/11 17:33
# @Author : shisuiyi
# @File : test_invest_flow.py
# @Software: win10 Tensorflow1.13.1 python3.9
from common.base_case import BaseCase
from common.data_handler import get_data_from_excel
from unittestreport import ddt, list_data
@ddt
class SuperInvestFlow(BaseCase):
name = '参数化的投资业务流'
cases = get_data_from_excel(BaseCase.setting.TEST_DATA_FILE, 'invest_flow')
@list_data(cases)
def test_invest_flow(self, item):
self.flow(item)
if __name__ == '__main__':
BaseCase.unittest.main()